Incident handling at Kayako
Mar 23, 2017 00:00 · 1973 words · 10 minute read
We at Kayako strive for the number of 9’s in our uptime metric. We want to ensure minimum service disruption for our customers, and therefore we need to work hard on the following two aspects:
- Identifying that an incident has occurred
- Minimizing the impact of the incident
Identifying an incident
Our goal is to identify an incident before our customer. It not only helps us in proactively informing our customers on the ongoing issues but also helps us to prepare our Support team better for the incoming queries. It is a step towards better customer experience, which is what Kayako is all about.
To achieve this goal, we have monitoring at multiple levels in our entire infra, and we are improving it continuously. Most of these monitoring tools are either integrated with Slack or Pagerduty so that our SRE team is the first one to know about these incidents.
Some of the things that we currently monitor are:
- Health of our servers (like load, memory-usage, io wait, etc.)
- Health of individual Kayako helpdesks (crons, emails, search, queues, realtime dispatch, etc.)
- Connectivity within our infra (for ex: if application is able to connect to the Database)
- Health of Database
- Any delays in outgoing emails
- Spam alerts
- Health of our microservices
- Trial sign-ups failures
- Timely DB backups
- Any suspicious activity
- Health of critical processes like Nginx, supervisord, etc.
…and the list goes on. Once we have identified an incident, it brings up to the next step:
Minimizing the impact of an incident
Incidents are inevitable, things do go wrong, but our goal is to minimize the impact on our customers. We have a Standard Operating Procedure (SOP) around incidents response, and one of the critical parts of that SOP is an issue channel.
We create a channel on Slack for every new incident (called an “issue” channel), all the relevant stakeholders join that channel, and all the discussion about the incident happen only in that channel. The issue channel remains open until we do a post-mortem, find the root cause of the issue and fix it. The channel is archived once we fix the root cause.
Before I go into the details of our SOP, let’s first start by listing down all the issue channels that we currently have. We follow convention as #issue-topic-ddmm. So if there is an issue with our crons on 12th March 2016, we will create a channel #issue-cron-1203.
|
|
207
207, that’s a lot of issues!
But before we conclude anything, let’s see what is the time range in which these channels span:
|
|
First issue channel: 2016-03-11 06:55:23
Last issue channel: 2017-03-23 00:43:10
Average number of issue channels per month: 16
Let’s see how many of these issue channels are active as of now:
active_issue_channels = list(filter(lambda x: not x["is_archived"], issue_channels))
print(len(active_issue_channels))
3
Only 3 active issue channels!
Active not necessarily mean that the issue is ongoing, it can also mean that the issue is resolved, however, the root cause analysis is pending (which is the case here).
Do you want to know what was my worst day in the last one year? Let’s find out
|
|
Worst day in last year: 2016-08-09
Total number of issue channels created on this date: 6
Let’s try to analyze the trend of issue channels over time. To find a trend, we need to need to know the archive date of a channel, which is not present in the issue_channels list that we have. Fortunately, Slack has an API to get the archive date of a channel.
|
|
Now we have archived dates in our issue_channels list. Let’s try to plot the number of open issue channels over time in the given date range. To plot this, we will create a range of dates for X-axis and the number of issue channels that were open on that date on the Y axis.
|
|
So we have our range on X-axis and the corresponding number of open issue channels on Y-axis. Let’s plot them:
|
|
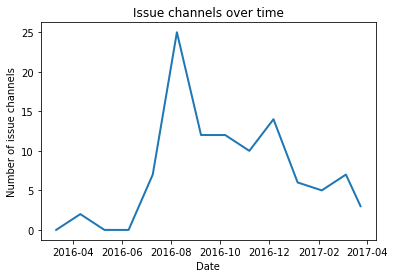
Interpreting the graph
We launched The New Kayako in July 2016, and there was a steep rise in the number of issue channels. Just like with any other product launch, things were not so stable. We worked hard on fixing the root issues and making sure that the problems don’t repeat. Whatever issues we encountered, they were fixed forever. The results you can see by yourself. There is a declining trend in the number of incidents. The system has become a lot more stable from where we started. We have spent countless nights to reach the current state.
By no way this is an ideal state, we are continuously improving and getting stable with every passing day.
Issue channels, hit or miss?
I would leave it to the readers to decide if this strategy was a success or a failure. I have shared a part of the data that we have on it.
Standard Operating Procedure for Incidents
Issue channel is just one of the many things that we follow to minimize the impact of an incident. Let me share some points from our SOP document on the incident response:
-
Change your mindset - quickly say the following things to yourself.
- This is an extreme situation and my normal behavior is not ideal in this context
- The customer is suffering because of us and it is paramount to restore services first - anyway possible
- We are not debugging, that is for later, we don’t care for root causes right now - only solutions
- I will lose my sense of time as I start working, I must put a timer that repeats every 10 mins so I realize the passage of time
- I may not be able to solve this alone
- I don’t need to know everything before I escalate. If it’s time to escalate, I will do it even with incomplete information.
- The escalation is a form of communication and the act alone has value.
- I am not the only person impacted by this problem. I am not the only person worried about it. But I am the closest to the action and therefore all communication starts at me.
-
Build context, answer the following questions as best as you can don’t spend more than two minutes on this
- Which component seems to be the source of this problem?
- What is the frequency or duration of this problem?
- What other components are affected by this behaviour?
- What is the severity of this issue? It’s critical or severe if one or more customers are facing a downtime
-
In the issue channel set the topic to a brief line about the problem and add names for SRE issue owner and Developer/Product Engineer issue owner, as applicable
-
Check the escalation matrix periodically and escalate as required
-
Update issue channel with summary of issue, cover the following points, if something is not known say its ‘UNKNOWN’
- Environment: Staging / Production
- Component responsible for problem
- Probable cause if known
- Frequency or Duration of issue
- Type: Self (Engineering), Unknown, Scale (any scalability problems etc), Vendor (AWS, Dynect, Sendgrid, Realtime etc)
- Estimated Time to recovery (If Unknown, take an educated guess is it a matter of minutes, hours, or days)
- Who is working to fix this
- Current action step
- Next action step
Summary
Production outages are extreme pressure situations, in such situations, we try to:
- Communicate as much as possible – to engineering teams, to support teams or any other stakeholders
- Minimize the downtime and impact
- Leave trails for finding and fixing root cause right afterward
- Escalate as required
I mentioned some of the tools and processes that we use to achieve these goals. They are not perfect, and we keep them improving based on the feedback. If you have similar processes in your company, drop a comment below and let us know!