My Internship At Kayako
Mar 2, 2016 00:00 · 2078 words · 10 minute read
This post was originally posted on Medium as a part of life at Kayako series.
This summer I got the opportunity to do an internship as a Product Engineer at Kayako. I was fresh out of college and looking for a chance to apply the knowledge that I learned at college. I accepted the offer straight away.
The internship was the perfect platform to kick start my professional career. It not only honed my technical skills, but also helped me to the understand the various aspects of how an organization like this works.
In this post I’ll briefly explain my internship project and how it impacted Kayako.
A Background to Kayako
Kayako is a cloud-based customer support software provider with over 35,000+ customers across the globe.
Kayako has team members based all over the world, with the main three offices are located in London, Gurgaon, and Jalandhar. Kayako’s CEO, Varun Shoor, oversees all the work from the London headquarters.
I was based in the Gurgaon office, where I worked for 3 months in the development team.
The Tech Stack
Kayako has rapidly adopted microservices architectural pattern and has broken down the monolith core application into a multi-tier application. Most of the microservices are developed in PHP on top of a framework, whereas some of them are developed in Golang.
We have an in-house PHP framework based on MVC architecture. It overcomes the shortcomings of the language. It has a strong caching mechanism, robust exception handling, worker & queuing system, ORM, integration with third party services like Slack, and lots of other interesting features.
We plan to open source the framework in future.
The entire tech stack of the company is humongous and beyond scope of this post. The project that was assigned to me during the internship was supposed to be developed in PHP using the framework. I later realized how much less efforts I had to put in because of the framework.
The Project
Since the rise of the internet, software can no longer be developed with a single language or geography in mind. Support for common and popular languages is now essential for the increased market reach and success of any product.
My project was to develop a microservice which automates the localization of Kayako. The project was crucial for the product as it will allow it to be accessible in several languages other than English. For those who are unfamiliar with the term localization, it is the process of adapting a product to local languages.
Language translation is a complex task. It cannot be done by simply replacing the values word by word. There are no standards for currency and numbers which are applicable for all the languages. Even the sequence (left-to-right or right-to-left) in which a language is read/written varies from language to language.
Just to give you an idea of complexity, there are more than 20 ways of saying “to get” in French!
Computers are dumb machines. It’s very difficult for them to understand the context. Machine translations are therefore very awkward and often produce hilarious results which make no sense at all. For example:
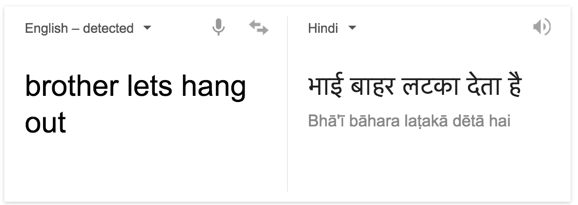
The above translated text in Hindi is equivalent of — Brother hangs me outside.
Therefore only a human can truly recognize the intent of a sentence.
In the current version of Kayako helpdesk, the translations are handled through a community driven translation portal–http://translate.kayako.com. The process of manually uploading language packs and then integrating them with each release is painfully slow and prone to errors. It does not stand strong against the rapid development pace of the product. Any such manual layer has an added maintenance cost which increases as the team grows.
Tools for translation
Transifex
We needed a system that was accurate, fast, and integrated with our continuous integration (CI) system. Whenever a new phrase gets introduced in the code, it should be automatically sent to human translators, and on completion of translations it should be automatically added to the platform.
We also didn’t want to lose the advantages of the community-driven translations, like verification or support for unpopular languages, so we decided to integrate the the whole system with the translation portal Transifex.
We chose to go with Transifex because it natively supports the translation service Gengo, which provides human translations. The rich web interface of Transifex would allow us to order translations from Gengo, as well as continue to support community-driven translations.
Transifex provides exhaustive APIs to update resources, add translations, add new resources, etc. An API was a critical requirement for us as we had to automate everything from within a script, which would not have been possible without it. However we soon realized that ordering translations of the phrases from Gengo is supported only through the web interface, and not through the APIs. It was a big problem.
Gengo
Gengo is a service which provides translations by real people across the globe. We realized that it also offers an API to order the translations. Therefore we decided to directly place order for translations by using the Gengo API, instead of placing them from Transifex API (which was not supported by Transifex).
Process of ordering a translation from Gengo is as follows:
- A request (job) is sent through the API.
- Gengo allocates the job to a translator.
- A translator picks up the job and starts working.
- When complete, the job is retrieved via API.
- We approves the completed translation.
The API is asynchronous. You don’t need to poll Gengo for the status of translations. A callback is fired once a translator finishes the job.
Gengo also has a comprehensive sandbox mode which is very helpful for testing out the APIs. It has support for pseudo credits so that no actual money is charged when placing orders for testing.
Joining the pieces together
We decided to use Transifex for managing the localization and Gengo for automating the translations. Our next step was to figure out how to fit the individual pieces together and integrate it with our CI system, Travis CI.
As there were quite a many systems involved — Gengo, Transifex, Travis, GitHub, and Deployment, I was overwhelmed by the requirements. But slowly, the things which were obscure started to make sense as we researched more.
Although I was itching to start coding, Varun Shoor suggested that I wait until we were absolutely clear about the complete flow. There were still some unanswered questions which could kill the project. We decided not to write even a single line of code until we had the complete flow, the database schema, and the API documentation ready.
I googled day in, day out, read the API documentations of Gengo and Transifex, wrote some demo scripts to see the APIs in action, and analyzed the Git branch flow followed in Kayako.
Whenever I wasn’t sure about anything, my mentor Pankaj was always available to help me out. He helped me to get things bootstrapped and gave me insights into how engineering at Kayako works. I also explored the framework and other cool projects that were going on at Kayako.
After few days of work, we finally came out with a proposal. It was my first real project proposal and I was nervous about it. I was really elated when Varun appreciated me for it.
Joining the pieces together
We decided to use Transifex for managing the localization and Gengo for automating the translations. Our next step was to figure out how to fit the individual pieces together and integrate it with our CI system, Travis CI.
As there were quite a many systems involved — Gengo, Transifex, Travis, GitHub, and Deployment, I was overwhelmed by the requirements. But slowly, the things which were obscure started to make sense as we researched more.
Although I was itching to start coding, Varun Shoor suggested that I wait until we were absolutely clear about the complete flow. There were still some unanswered questions which could kill the project. We decided not to write even a single line of code until we had the complete flow, the database schema, and the API documentation ready.
I googled day in, day out, read the API documentations of Gengo and Transifex, wrote some demo scripts to see the APIs in action, and analyzed the Git branch flow followed in Kayako.
Whenever I wasn’t sure about anything, my mentor Pankaj was always available to help me out. He helped me to get things bootstrapped and gave me insights into how engineering at Kayako works. I also explored the framework and other cool projects that were going on at Kayako.
After few days of work, we finally came out with a proposal. It was my first real project proposal and I was nervous about it. I was really elated when Varun appreciated me for it.

This proposal was short-lived as it missed out many important details. Soon we came out with another iteration of the proposal which included DFDs, API design, database design, milestones and a tentative timeline along with visible challenges in sight. My experience with writing project proposals for open source projects in Google Summer Of Code came in handy.
The intricate nature of the project meant we had to produce multiple iterations of the workflow before we got it right. We worked on the proposal for around two weeks and what came next was what I was craving for — coding.

The Part I Was Waiting For — Coding!
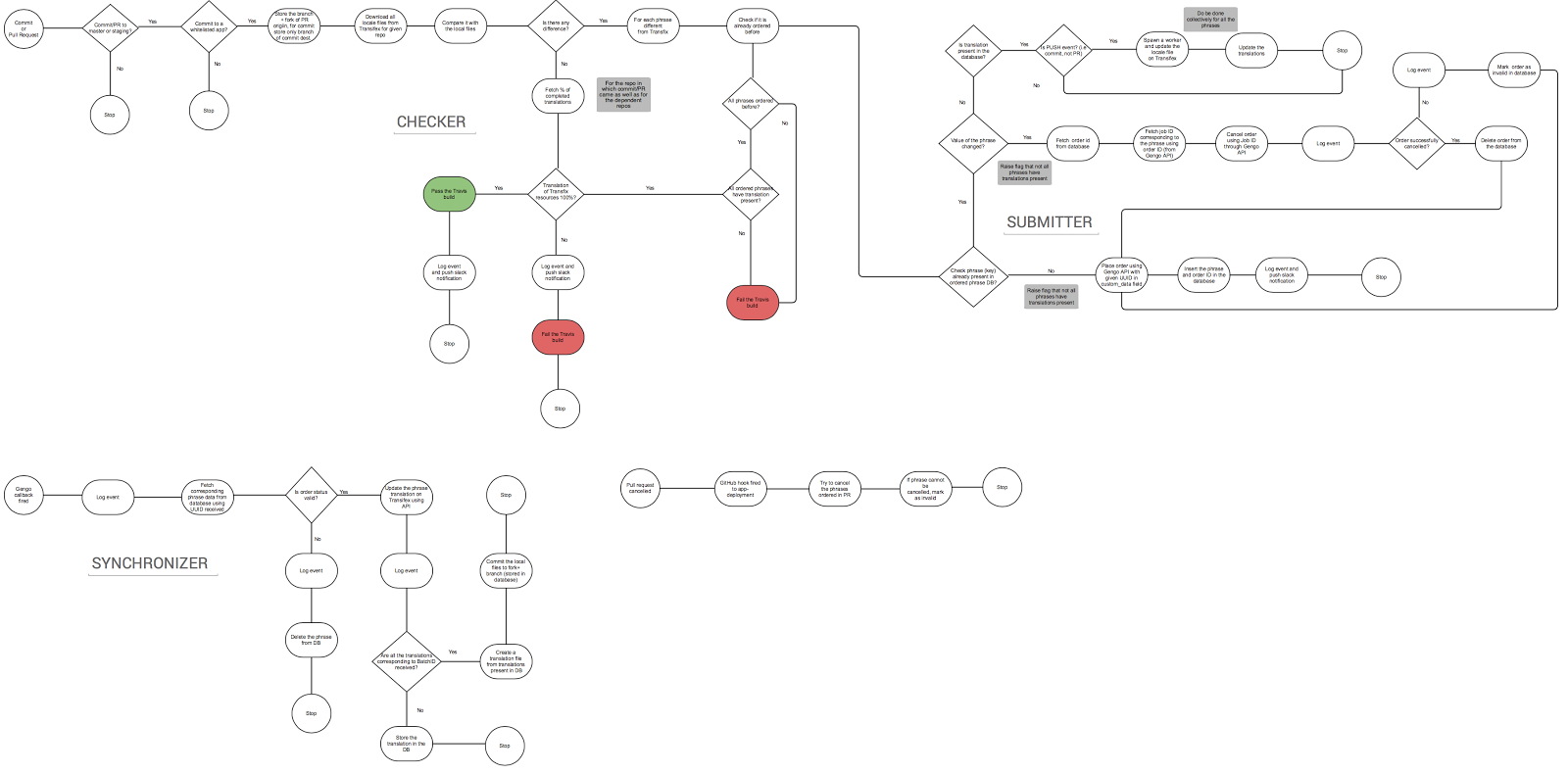
We divided the big complex system into three easy to digest submodules: Checker, Submitter, and Synchronizer.
When a commit or a pull request comes to a GitHub repository, the checker gets activated. It checks if the translations of the phrases present in the repository are complete or not. If not, the build fails and the submitter gets activated which places an order for the phrases which are not yet translated.
Once the translations are completed, the synchronizer commits the translations back into the same branch. The commit triggers a build, but this time it passes because the translations are now present.
Learnings From Building the Workflow
In the initial versions of the workflow we missed out some of the key aspects like:
-
Travis [skip ci] feature: If someone uses [skip ci] in the commit description then the build is skipped. So we also need to check the phrases which are not part of current commit or pull request (PR).
-
Cancelling orders: If a new phrase was modified before its translation arrives, we need to cancel the previous order and place a new one. Also, if a PR is closed before merging, we need to cancel the orders placed in that PR.
-
Batch commit: Since each phrase corresponds to a new job, the callback of translations of each phrase comes as a separate request. Creating a new commit for every phrase was inefficient. We now commit in batches.
-
Commit branch: We were committing translations to Kayako branch instead of the branch from which a PR was originating. It is important to commit to same branch because the build will only restart (and pass) when a commit comes to that branch.
-
Duplicate translations: Two identical phrases which were in different files were ordered separately, resulting in duplicate orders. All the issues listed above, along with several other pitfalls, were fixed in the subsequent iterations. We also developed a uniform naming scheme so that each phrase can be uniquely mapped to a file and a repository. This was required to commit the translations back to the correct file in the correct repository when a callback is received from Gengo. With a clear understanding of each and every part, the coding phase went very smoothly. The alpha version of the project was ready well ahead of schedule!
Putting the Cherry On Top
We realized that we need to show the status of translations in the PR itself. So we used the GitHub statuses API. For the first time in my life, I was happy to see a red cross in front of my PR.
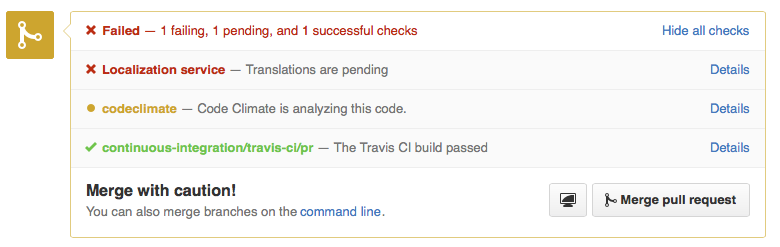
Conclusion
The careful planning and designing of this project was key to its success. This helped us to foresee problems, allowing us to fine-tune the flow without much resistance. Changing the structure of an existing code is much more difficult and time consuming than doing it with a pen and paper.
It was the most interesting project which I’ve ever worked on, particularly because it involved synchronization of so many services, all in one project!